영상에 하드코딩된 내장자막 자동추출 가이드 2 - 설치 상세설명
앞선 글에서 Video Sub Finder와 Google Docs OCR V3 를 사용해서
동영상에 하드코딩된 내장 자막을 자동으로 추출하는 방법을 설명드렸습니다.
이번 글에서는 프로그램 준비와 설치 과정을 설명드리려고 합니다.
약간 복잡할 수 있지만, 한번 해놓고 나면 더이상 재설치나 설정 같은게
전혀 필요 없습니다.
기본적으로 Google Docs OCR V3는 설치가 필요 없는 프로그램입니다.
아래의 V2, V3 2가지 버전 모두 다운로드 합니다.
Google Docs OCR V2 2022 다운로드 페이지
https://mega.nz/file/HpgDhQBT#ooUTkN2wTwsS5Hncx9fCJfLn2VncqS17_WyDrfPTaAY
Google Docs OCR V3 다운로드 페이지
https://mega.nz/file/i04gjSzb#D26EBYJguBzWAeN5ScF6xJHzCzzISdXKcl8Laeqyaoo
보시면 아시겠지만 Google Docs OCR 압축파일이 5kb 밖에 안됩니다.
웬만한 자막파일보다 용량이 작네요 ㅎㅎ
01. Python 및 스크립트 설치
python 을 다운로드 합니다. 윈도우 버전에 따라서 32/64bit 중에서 다운로드 합니다.
python 다운로드 페이지
1. Python 3.8 이상 버전을 다운로드 해서 설치합니다.
2. C:\Users\사용자계정\AppData\Local\Programs\Python\Python39\Scripts
폴더에 들어가서 폴더 주소창에서 cmd를 실행합니다.
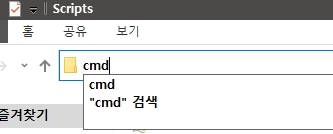
3. 명령프롬프트가 실행되면
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
이 명령 전체를 복사해서 붙여넣고 엔터를 칩니다.

pip install oauth2client
이 명령도 복사해서 붙여넣고 엔터
이렇게 두가지 스크립트를 설치하면서 python 설치를 마무리 합니다.
이제 구글 클라우드에서 구글 드라이브 api가 포함된 json 파일이 반드시 필요합니다.
이 파일을 다운로드 하는 과정이 사실상 프로그램 설치와 설정 과정의 절반이나 마찬가지입니다.
제가 확인해본 결과 Google Docs OCR V3 버전은 구글 드라이브 로그인
파일을 생성하지 못하는 오류가 있는 듯 합니다.
그래서 일단 V2 버전을 통해서 token.json을 생성한 이후에,
V3 버전 폴더에 credentials.json, token.json 두개의 파일을 복사할 것입니다.
02. credentials.json 생성 및 다운로드
구글 클라우드 계정을 만들고 json파일을 생성해서 다운로드 하는 튜토리얼
영상은 아래에 있습니다.
https://mega.nz/file/Pkw2xZYC#_8u-v9gy0LFoBHS57LUZ_IK9UvHPyytSE7DJt5PeJvQ
이 영상은 영문 웹페이지를 통해서 설명하고, 또 오래전에 만들어졌기 때문에,
우리가 사용할 현재 한글 구글 클라우드 웹페이지와 구성이 약간 다릅니다.
영상을 일단 한번 본 후에, 아래에 제가 직접 프로젝트를 만들고 json 파일을
다운로드 하는 과정을 설명한 내용을 보시면 좀더 쉽게 따라하실 수 있을 겁니다.
https://console.cloud.google.com/ 에 접속합니다.
물론 구글 아이디가 있어야 하고, 구글에 로그인 되어 있어야 합니다.
뭐 이건 기본이겠죠.
1. 상단에 프로젝트 선택을 클릭합니다.

2. 프로젝트 선택창이 보이면, 새 프로젝트를 클릭합니다

3. 프로젝트 이름은 자신이 원하는 적당한 이름으로 만듭니다.
저는 이번에 cineaste로 만들어 보도록 하겠습니다
프로젝트 이름을 적고, 만들기를 클릭합니다.

4. 생성되면 프로젝트 선택을 클릭합니다.
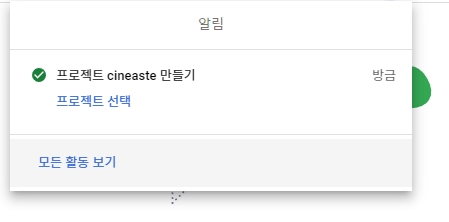
5. 옆에 메뉴에서 <OAuth 동의 화면> 항목을 찾아서 클릭합니다
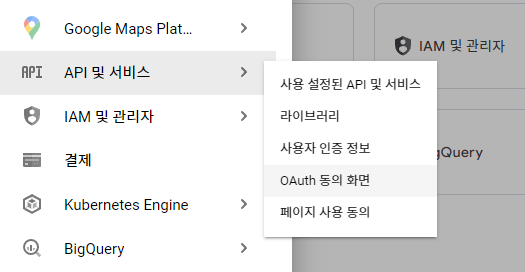
6. Uset type 에서 <외부>를 선택해주고 <만들기>를 클릭합니다
7. 다음 앱정보에서 앱이름은 처음에 설정한 이름대로 cineaste로 설정합니다

8. 사용자 지원 이메일은 자신의 구글계정 이메일을 자동으로 입력해 줍니다
9. 밑에 개발자 연락처 정보에도 자신의 구글계정 이메일을 복사해서 입력합니다
10. 맨 밑에 <저장 후 계속>을 클릭합니다
11. 다음 페이지에서도 <저장 후 계속>을 클릭해서 넘어갑니다.
12. 테스트 사용자 페이지에서도 <저장 후 계속>을 클릭해서 넘어갑니다.
13. <앱 등록 수정> 페이지가 나오면 하단 <대시보드로 돌아가기>를 클릭합니다
14. OAuth 동의 화면이 나오면 <앱 게시>를 클릭하고 <확인>을 클릭합니다
15. 이제 옆에 메뉴에서 <라이브러리> 항목을 클릭합니다
16. 라이브러리 페이지에서 구글 드라이브 api를 찾아서 클릭합니다
17. 다음 <사용>을 클릭합니다
18. 이제 옆에 메뉴에서 <사용자 인증 정보> 항목을 클릭합니다.

19. 상단에 <사용자 인증 정보 만들기>에서 OAuth 클라이언트 ID
항목을 클릭합니다.

20. 어플리케이션 유형은 <데스크톱 앱>으로 선택합니다.

21. 이름은 OCR V3로 적어주고, <만들기>를 클릭합니다.
22. 이제 OAuth 클라이언트 생성됨 창 하단 <JSON 다운로드>를 클릭합니다
23. 이제 컴퓨터에 상당히 긴 이름의 json 파일이 다운됩니다.
이 파일의 이름을 credentials.json 으로 바꾸어 줍니다.
24. 이제 앞서 다운로드해 두었던 V2 버전 폴더 안에
credentials.json을 복사합니다.
25. python 3.8 이상 버전과 스크립트가 설치된 상태여야 합니다.
03. token.json 생성
01. main.py를 클릭하여 실행합니다.
02. token.json 파일 생성을 위해 구글 계정으로 로그인하는
인터넷 창이 뜨게 됩니다

03. 계정 선택 cineaste 아래 자신의 구글 계정을 클릭합니다
04. 다음 페이지에서 아래에 <고급>을 클릭합니다

05. <cineaste(으)로 이동(안전하지 않음)> 을 클릭합니다
06. 다음 페이지에서 <계속>을 클릭하면 token.json 이 생성됩니다
07. 이제 생성된 credentials.json과 token.json을 따로 저장한 후에
이것을 앞서 다운로드한 V3 버전 폴더로 복사해서 실행하면 됩니다.
두개의 json 파일을 확보했으니 V2 버전은 더이상 필요없습니다.
08. 앞서 말했듯이 프로젝트 이름은 자신이 적당하다고 생각하는
이름으로 설정하면 됩니다.
09. python과 스크립트를 설치해두고, credentials.json과 token.json 두개의
json 파일을 V3 폴더에 복사했다면 실행 준비는 끝난 것입니다.
04. 여러개의 영상 동시작업
여기에 더해서 여러 개의 영상을 한꺼번에 작업해야 할 경우에 필요한
프로그램을 설명하겠습니다.
프로그램 사용법은 아래의 영상을 참고하시면 됩니다.
1. 여러개의 영상을 한번에 작업할 수 있는 BATCH HARDSUB TO SRT
다운로드 링크
https://mega.nz/file/T4wTmJZZ#onN8cY20T-Mk6KXkvHIs2K0u9JN52ZXmQGm_f_ZjRd0
2. 구글 드라이브의 파일을 자동으로 삭제해서 청소할 수 있는 Delete_All_Files_Google_Drive
다운로드 링크
https://mega.nz/file/20BClQaR#4W3jm9bLdx56LNX7ecYAleYS3oak7clOr-tRZ8LaezY
그리고 앞서 스크립트를 설치했던
C:\Users\사용자계정\AppData\Local\Programs\Python\Python39\Scripts 로 이동한 후
앞서 했던 것처럼 폴더 주소창에서 cmd를 실행합니다. 명령프롬프트가 실행되면
pip install pandas
이 명령어를 복사해서 붙여놓고 엔터를 쳐서 스크립트를 설치합니다.
압축파일을 다운받고 압축을 푼 다음에 각각의 프로그램 폴더에, 마찬가지로 두개의 json을
복사해서 넣어주기만 하면 모두 즉시 사용이 가능해지게 됩니다.
Google Docs OCR V3 와 BATCH HARDSUB TO SRT. 이 두가지 프로그램의 차이점은
한개의 영상만을 작업하는가, 아니면 여러개의 영상을 순서대로 작업할 수
있는가의 차이입니다.
한개의 영상만 작업한다면 Google Docs OCR V3 를 사용하는 것이 편합니다. 왜냐하면
구글 드라이브의 특정폴더를 설정해서 여기에서 작업할 수 있기 때문에, 작업이 완료된
이후에 그 폴더만 삭제하면 구글 드라이브 정리가 편하기 때문이죠.
그에 비해서 BATCH HARDSUB TO SRT 는 구글 드라이브에서 그냥 작업하기 때문에
작업이 완료된 이후에 남은 작업파일들을 구글 드라이브에서 정리하는게 상당히 번거롭습니다.
이것도 특정 폴더에서 작업할 수 있으면 삭제가 편한데, 그게 안되나 봅니다.
05. 구글 드라이브 정리
10개가 넘는 영상의 자막을 한꺼번에 작업할 경우 작업이 끝난 이후에 수천개에서 만개가
넘는 파일이 구글 드라이브에 쌓이게 되므로 삭제해 주어야 합니다. 제가 한번 수동으로
해봤는데, 사람이 할짓이 못됩니다. 그래서 자동으로 삭제해 주는 프로그램이 필요합니다.
이 Delete_All_Files_Google_Drive 프로그램을 사용해서 자동으로 구글 드라이브에 있는
모든 파일을 삭제하면 됩니다. 노가다는 컴퓨터에게 맡기고 각자 할일 해야지요.
삭제에 필요한 시간은 자막생성에 필요한 시간과 비슷한 정도입니다. 원래 구글 드라이브에서
파일 삭제는 좀 느리게 진행됩니다. 자동으로 진행되니까 실행만 시켜놓고 차한잔 하시거나,
자기 할일 하시면서 완료를 기다리면 됩니다.
CPU 사용률도 1-2% 정도로 가볍기 때문에, 게임이나 다른 컴퓨터 작업을 하시면서 완료를
기다려도 무방합니다.
<<<<<<<<<<<<<<<<<<<<<<<<< 주의 >>>>>>>>>>>>>>>>>>>>>>>>
Delete_All_Files_Google_Drive 프로그램 폴더 안에 4-Delete_All_Files_One-By-One-Forever.py 를
실행하면 구글 드라이브 안에 있는 모든 파일이 삭제됩니다. 구글 드라이브에 개인적인 파일들을
업로드 해두었다면 반드시 컴퓨터에 백업한 이후에 이 기능을 실행해야 합니다.
구글 드라이브에 있는 모든 파일이 삭제됩니다!!!!
구글 계정 이메일 첨부파일이나 구글 포토등, 구글 드라이브 이외의 파일은 삭제되지 않으니
그것은 걱정하지 않아도 됩니다.
Delete_All_Files_Google_Drive 에 관한 보다 자세한 기능을 알고 싶다면 아래 링크의 영상을
참고하시면 됩니다.
06. 하드디스크 파일 정리
각각의 프로그램 폴더안에 Credentials.json, token.json을 넣어두고 필요할때마다 권한이
설정된 이 파일들이 들어있는 폴더째로 복사해서 그 폴더 안에서 자막 제작작업을 하고,
작업이 끝나면 그 폴더를 삭제해 버리면 편합니다.
작업할때마다 1회용 폴더 복사를 하고 지우는거죠.
준비과정이 꽤 복잡하다고 느껴질 수 있겠지만, 일단 Credentials.json, token.json을 확보하고 나면
다음부터는 설치작업은 더이상 필요없고 모든게 클릭 한번으로 끝나기 때문에 너무나 편하게 느껴지실
겁니다. 전부 자동이니까요.
앞선 글에서도 설명드렸듯이 이 프로그램들은 구글 클라우드의 유료 기능을 사용합니다만
구글이 최초 계정 생성때 40만원을 공짜로 충전해 줍니다. 우리는 상업적인 대용량 OCR이 아닌,
고작해봐야 100메가 정도 되는 자막 이미지 파일에 OCR을 사용하는 겁니다.
제생각으로는 하드코딩 된 자막 추출을 1080p 고화질 영상으로만 1000개 넘게 작업해도
구글이 준 40만원을 다 쓰지 못할 겁니다. 개인이 이런 자막 추출작업을 1000개 넘게 작업할
일이 있을지 상상하기 어렵네요. 어쨌든 이런 용도로는 공짜나 다름없습니다.
그리고 다음글에서는 여러개 혹은 단일 IDX/SUB 파일을 srt로 자동변환하는 프로그램에
관해서 자세히 설명하고자 합니다.
idx/sub를 srt로 자동변환 가이드
https://cineaste.co.kr/bbs/board.php?bo_table=psd_capmakef&wr_id=31014







이미 몇 분이 성공적으로 잘 사용하시는걸 보면 제가 쓴 가이드는 이상 없어 보입니다. 더이상은 도움을 드릴 수 있는게 없네요.
잘 되시길 바랍니다. 브라우저에 구글이 로그인된 상태인지 확인 한번 해보시는 것 말고는 생각나는게 없네요. 그리고 저는 마소 엣지를
기본 브라우저로 하고 있습니다.


저는 러닝타임 거의 3시간 짜리 중국어 영화에 하드 인코딩 된 자막을 추출해 봤는데..
인식율이 아주 좋습니다!
Sync.도 잘 맞고요!
중국어 영화는 영상안에 중국어와 영어가 하드 인코딩 경우가 많아서
인터넷에 굳이 .smi .srt 같은 원문 자막 파일 자체가 없습니다.
그래서 중국어 영화 자막을 만들려면 제일 힘든게 대사를 하나하나 수동으로 찍어서 입력하고, 모든 Sync.를 수동으로 맞추는 거였는데..
이 기능을 사용하면 작업이 많이 수월해 질 것 같습니다!
좋은 자료와 자세한 설명 대단히 감사합니다!
역시 세상엔 고수들이 많다는 걸 다시 금 느끼네요! ㅎㅎ