영상에 하드코딩된 내장자막 자동추출 가이드 - 1
씨네스트에 기존에 소개된 여러가지 하드코딩 자막 추출법들을
사용해 봤는데, 인식률이 좋으면 불편하고, 편리하다 싶으면
글자 인식률이 형편없고, 딱 만족스러운게 없더군요.
그런데 인터넷을 찾아보다가 편의성과 완벽한 인식률 모두를 만족하는
좋은 프로그램이 있어서 소개할까 합니다.
제가 소개하는 이 프로그램은 구글 OCR 기능을 이용하지만 사람의 손으로
하나하나 처리할 작업을 자동적으로 처리해서, 그냥 실행시켜 놓고 기다리면
OCR 처리한 자막을 뚝딱 내놓는 프로그램입니다.
아래 이미지는 오탈자 수정이나 띄어쓰기는 전혀 손대지 않고 10분 정도 시간을
투자해서 subtitle edit 의 기본기능으로 살짝 다듬어주고, 불필요한 문장기호
몇 개만 삭제한 후에 완성한 추출자막입니다.
상당히 긴 분량 내에서 띄어쓰기 오류나 오탈자를 단 하나도 찾아볼 수 없습니다.

이정도면 99.9% 의 정확도라고 봐도 괜찮을 듯 합니다
Video Sub Finder로 자막 이미지를 추출해서 자막 OCR 프로그램이 있는
폴더로 복사하고 실행버튼을 누르는 것 말고 아무것도 하지 않아도 됩니다.
모든 과정은 자동으로 처리됩니다.
어떤가요? 너무 편리하겠죠? 자막 제작자의 시간은 너무나 소중하니까,
시간을 아껴야죠. 귀찮은 노가다는 컴퓨터에 맡기구요.
아래 링크에 프로그램 설치방법과 사용법을 설명하는 간단한 설명 동영상이 있습니다.
설치와 준비과정은 약간 까다로울 수 있기에 다음글에서 설명하기로 하고
일단 기본적인 사용법부터 캡쳐 이미지를 통해서 설명하겠습니다.
01. 자막 이미지 추출
익숙한 Video Sub Finder로 자막 이미지를 추출합니다.
Video Sub Finder 다운로드 페이지
https://www.videohelp.com/software/VideoSubFinder
자신의 윈도우 버전에 따라서 32/64bit 구분해서 다운로드 하시면 됩니다

02. 영상에서 자막이 나타나는 영역을 라인으로 설정해주고,
Run Search를 클릭하여 실행합니다.
기존에는 OCR 인식률을 높이기 위해서 ISA이미지 파일을 이용하는 경우가
많은데, 우리는 구글 OCR을 사용할 것이기 때문에, 원본 RGB 이미지를 그대로
사용합니다.
그래서 Run Search 를 클릭해서, RGB 이미지를 추출하는 작업까지만 진행하고
다른 기능은 사용하지 않을 겁니다.

RGB 폴더에 이미지를 그대로 사용할 경우 보시다시피 텍스트가 없는 이미지들이
많이 포함되서, 비어있는 자막라인이 생기게 됩니다. 그리고 하나의 자막라인을 두개,
혹은 세개의 이미지 파일로 나누는 경우도 있어서 똑같은 자막이 두 세줄씩 생길 수 있습니다.
03. Video Sub Finder의 옵션 조정
이 문제는 Video Sub Finder의 옵션을 조정해 주어야 합니다.
고화질일 경우 캡쳐 이미지가 깨끗하기 때문에 크게 차이가 없지만
저화질일 경우, 자막 주변의 노이즈나 작은 물체들, 색상의 변화 같은
것들을 Video Sub Finder 가 문자기호로 인식할 확률이 높아집니다.
자체자막으로 되어 있는 영상들은 보통 화질이 좋지 않은 경우가 많아서
이러한 불필요한 자막이미지들이 많이 생성되는 것이죠.
이 문제는 Video Sub Finder의 옵션을 조정해 주어야 합니다.
Video Sub Finder 의 하단에 Settings를 클릭합니다.

Min Symbol Height (in % to Full Image Height) : 이 옵션은 전체 화질에
비교해서 문자기호 같은 것들이 어느정도 크기인지 설정해 주는 옵션입니다.
기본설정이 0.02로 되어 있는데 이 수치는 너무 민감합니다. 저화질이라면
이 옵션의 수치를 키워주지 않으면 작은 노이즈까지 문자기호로 인식하게 됩니다.
그래서 불필요하게 중복이미지나 텍스트가 없는 비어있는 이미지를 많이 생성합니다.
그리고 나중에 결과물에서 노이즈들이 문자기호로 인식되어 수정작업 시간을
불필요하게 더 잡아먹는 원인이 됩니다.
저의 추천값은 360p / 450p = 0.05 / 720p = 0.04 / 1080p = 0.03 입니다.
즉 저화질일수록 수치를 높게하고, 고화질일수록 수치를 낮게 설정하는 것입니다.
저의 추천값보다 더 높게 설정할 경우 오히려 자막이 누락되어 빠지는 현상이
발생하므로 주의깊게 설정하셔야 됩니다.
화질에 따라 이 옵션을 조정해 줍니다. 그러면 중복이미지나 빈 이미지의 생성을
상당부분 방지할 수 있습니다.
그렇지만 완전히 방지할 수 없기 때문에 나중에 Subtitle Edit를 사용해서
좀 더 정밀하게 수정할 것입니다.
추출된 자막 라인 이미지 파일이 937개네요. 이것은 제가 Video Sub Finder의 옵션에서
수치를 조정하지 않고 기본값인 0.02 그대로 추출했기 때문에 많은 파일이 생성된 것입니다.
옵션 설정에서 수치를 최적화 한다면 보다 적은 갯수가 생성 됩니다.

작업이 완료될때까지 차 한잔 하거나, 다른 볼일 하시면서 기다리면 됩니다.
CPU 사용량은 1-2% 정도로 아주 가볍기 때문에, 컴으로 게임이나 다른 걸
하시면서 기다려도 자막 작업에 지장을 주지 않습니다.
20분 걸려서 작업이 완료되었습니다. 원본 파일이 고화질이라면 아마 30분 정도
걸렸을 겁니다.

훌륭합니다. 아주 정확하게 인식 불량 없이, 띄어쓰기도 거의 정확합니다.
역시 구글이네요. 참고로 위의 이미지는 옵션 수치를 조정했을 때입니다.
그렇지만 텍스트가 없는 이미지 파일과 하나의 자막 라인이 두세개로 분리된
이미지들이 포함된 RGB 폴더의 파일을 사용했기에, 앞서 예상했던 것처럼
비어있는 자막줄과 두 세줄로 분리된 자막줄들이 눈에 보입니다.
08. 빈줄 삭제와 동일한 라인 병합
이제 이것을 Subtitle Edit의 <일반적인 오류수정> 기능과 <동일한
텍스트라인 병합하기> 기능으로 정리합니다.
<일반적인 오류수정> 기능에는 빈 줄을 제거하는 옵션이 있습니다.
이 기능으로 텍스트가 없는 이미지파일 때문에 생긴 비어있는 라인을
제거합니다.
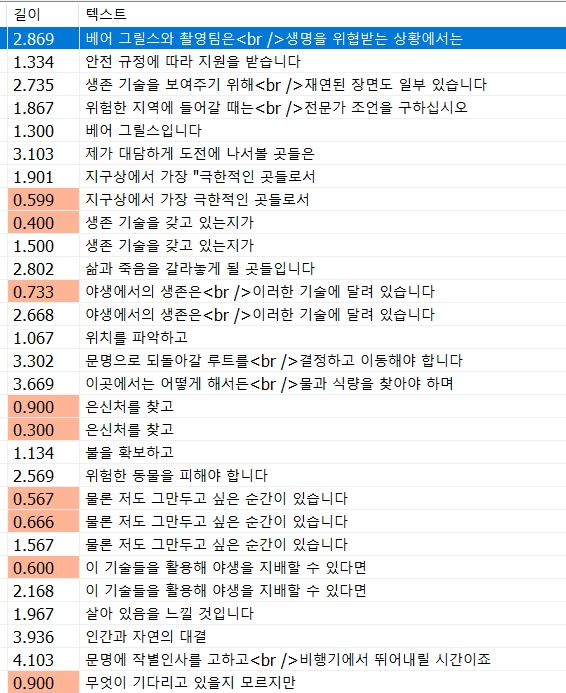
훌륭하게 비어있던 텍스트 라인이 제거되었습니다.
다음으로 <동일한 텍스트 라인 병합> 기능을 실행합니다.

01. Google Docs OCR V3는 구글 클라우드 계정에서 구글 드라이브
api를 사용합니다. 구글 클라우드 계정을 만들면 시작할때 트라이얼
40만원 정도를 구글이 무료로 충전해 줍니다.
제가 지금까지 이 프로그램으로 영상 100개 가까이 하드코딩된 자막파일을
추출했지만, 40만원 중에 1만원도 사용 못했습니다. 자막 1000개를 추출한다고
해도 10만원도 안되네요. 사실상 무료니까 원하시는 하드코딩된 영상들에서
자막 마음껏 추출하세요.
02. 프로그램의 실행을 위해서는 구글 클라우드 api가 포함된 credentials.json과
구글드라이브 자동로그인을 위한 token.json. 두개의 json 파일이 필요합니다.
이것을 생성하는 방법에 대해서는 제가 쓴 다음 게시물을 참고하시면 됩니다.
제가 상세하게 설명해 놓고, 참고할 동영상도 있으니 한번 읽고 따라해 보시면
몇 분 이내에 충분히 준비가 가능할 것이라고 생각합니다.
03. 이 두개의 json 파일을 Google Docs OCR V3 폴더 안에 집어넣어 두고,
이 폴더를 필요할 때마다 복사해서 사용하고 작업이 완료되면 그냥 삭제하는
방식으로 1회용으로 쓰면 편합니다.
왜냐하면 작업이 끝나고, 작업에 사용된 image 파일이나 구글드라이브에서
OCR 인식이 완료된 수백, 수천개의 텍스트 파일 등등이 컴퓨터에 남게 되기
때문에, 이걸 일일이 삭제하고 청소하는게 더 번거롭거든요.
그냥 json 파일이 들어있는 프로그램 폴더를 복사해서 1회용으로 쓰고 삭제하고,
다시 복사해서 쓰고 삭제하는 식으로 쓰는게 좋습니다. 저는 이런 방식이 편합니다.
04. 그리고 1시즌 전체 10개 이상 영상을 작업해야 한다면 BATCH HARDSUB TO SRT 를
사용해서 여러개의 영상을 순차적으로 처리합니다. 이 프로그램은 구글 드라이브에
특정한 폴더에서 OCR 작업을 하지 못하고, 폴더 밖에서 그냥 처리합니다.
만일 한 시즌 16개 영상이라면 자막 이미지 파일이 수천개에서 1만개 가까이
구글드라이브에 남게 될 겁니다. 특정한 폴더에 담을 수 없기 때문에 지저분해집니다.
그거 전부 삭제하고 청소한다면 시간이 한참 걸리게 됩니다.
05. 그래서 BATCH HARDSUB TO SRT로 여러개의 영상을 작업한다면
Delete_All_Files_Google_Drive 프로그램을 사용해서 구글 드라이브에
있는 모든 파일을 자동으로 삭제합니다.
정리하는 작업도 시간이 걸리고, 귀찮은 일이죠. 실행시켜놓고, 자기 할일 하면
정리되는 겁니다. 자막 제작자의 시간은 소중하니까요.
06. 다만 이 프로그램을 사용하면 구글 드라이브의 모든 파일이 삭제되므로 기존에
구글드라이브에 필요해서 업로드 해둔 파일이 있다면 컴퓨터에 백업한 후에 실행해야 합니다.
07. 또 BATCH CONVERT MULTI IDX/SUB TO SRT를 사용한다면, dvd나 블루레이에서
한시즌 전체 IDX/SUB를 추출한 다음, 폴더에 넣고, 실행 한번만 누르면 srt 자막으로
모두 자동으로 변환 됩니다.
08. 참고로 이 프로그램들은 아랍쪽 프로그래머가 만든 것 같습니다. 한류드라마 중심으로
아시아 드라마 자막작업을 많이 하는거 같은데, 어쩌면 이 프로그램도 한류 덕분에 만들어진
것인지도 모르겠습니다.
전체적인 작업과정을 요약하면
1. Video Sub Finder 로 영상의 모든 자막 대사라인을 하나하나 뜯어서 이미지파일로 저장
2. Google Docs OCR V3 가 이 이미지들을 하나하나 구글 드라이브에서 업로드
3. 구글 드라이브에서 이것을 OCR 작업해서 텍스트 라인으로 하나하나 변환
4. 이 텍스트들을 하나하나 컴퓨터에 다운로드
5. 다운로드된 텍스트들을 하나의 자막으로 완성
6. Subtitle Edit 를 사용하여 자막 정리
7. 최종적으로 오탈자와 불필요한 기호들을 수동으로 수정
이런 프로세스가 되겠네요. 작업 단계를 거칠때마다 수백, 수천, 때로는 만개가 넘는
이미지나 텍스트 파일이 남게되는데, 각 단계마다 이걸 삭제/청소하는게 좀 귀찮을 수
있습니다. 그렇지만 그 삭제도 자동으로 되게끔 프로세스를 마련해 두었습니다.
한두번 해보면 변환과 삭제작업은 컴퓨터만 노가다를 할 뿐이고, 사람은 최종적으로
오탈자 수정 같은 작업을 하면 되는걸 알 수 있을 겁니다. 실제로 들어가는 사람의
노력은 영상 하나당 30분 이내로 충분할 겁니다.
두세번 해보고 프로세스에 익숙해지면 번거롭기보다는 편하게 느껴질거라 생각합니다.
이 유튜브 채널에 전체적인 설치방법과 사용설명이 나와 있으니 참고하시면 됩니다.
https://www.youtube.com/@MrKingGM
다음글에서는 프로그램을 실행하기 위한 준비과정을 좀더 상세하게 설명하겠습니다.
이 글만으로 프로그램을 실행할 수는 없습니다. 필요한 파일들이 있기 때문이죠.
그래서 반드시 다음글을 읽어야 프로그램의 실행이 가능합니다.
다음글에 각각의 프로그램들의 구체적인 다운로드 링크와 사용팁들을
설명해 놓았습니다.
다음글 링크
https://cineaste.co.kr/bbs/board.php?bo_table=psd_capmakef&wr_id=31011
그리고 완성된 자막을 원본과 동일하게 수정하면서도 빠르게 작업할 수 있는
저 나름의 방법을 소개한 글도 읽어보신다면 유익할 겁니다.
Sub 변환자막 및 내장 추출자막 완벽하게 수정하는 가이드
https://cineaste.co.kr/bbs/board.php?bo_table=psd_capmakef&wr_id=31045









저는 중국어 영화만 번역 작업을 하는데, 중국은 땅덩어리도 크고, 다민족에 지방마다 방언도 심해서
자국 영화임에도 중국어 자막을 꼭 넣습니다.
저는 그렇게 영상에 하드 코딩된 영상을 보고 번역을 하지요~
당연히 자막도 영상을 보면서 일일이 수동으로 때려넣고, 나중에 Sync.도 수동으로 다 맞춘답니다!
이게 번역보다 더 시간이 많이 걸리고 완전 쌩노가다인데요 ㅎ
만약 이 방법이 유효하다면 저에게 큰 도움이 될 것 같습니다!
우선 알려주신대로 차근차근 따라 해보고 잘 안되는 부분이 있으면 문의드려도 될까요? ㅎ
정성 가득한 글에 다시 한 번 감사를 드립니다!
720p,1080p 몇개 작업해본결과 video sub finder 셋팅값을 terilary image processing - height 값을 0.05로 할경우 중간 중간 대사들이 누락된채로 이미지가 생성됩니다
0.05는 대사들이 누락될수가 있으니 위험하고 왠만하면 0.04정도가 적당한 세팅인것 같아요
0.04로 몇개의 동영상을 테스트해보니 아직 대사들이 누락되거나 그런 경우는 안생겼습니다
빈줄제거는 처음부터 하는것보다는 모든 작업이 끝난후에 하는걸 추천합니다
빈줄에 간혹 대사가 빠진 구간이 있기도 하거든요. 그런데 이미 처음부터 빈줄 삭제해버리면 나중에 그 부분 채워넣을때 번거롭거든요