Subtitle Edit 최신버전 섭변환 작업창 모습
방식은 subresync와 같고요 (단축키도 같음)
타이핑한 데이터가 저장되기 때문에
재타이핑할 필요가 없어집니다.
주의 사항
오류 허용을 '0'으로 설정해줘야
오차없이 변환되는 듯하네요
도중에 오타가 나도 전혀 문제될 게 없는 것이 잘못 입력된 데이터를 찾아서 삭제 후 재입력하면 그만입니다.

애니라 그런가 오디오 파형이 작업하기에 아주 수월하게 뽑혔네요
싱크 안 맞는 부분이 있어서 수정할 때는 오디오파형의 도움을 받곤 합니다.







23 Comments





요즘...
제가 베타버전으로 작업을 하는데...
정말로 편합니다....
일부 단어의 경우 한번 잘못 저장하면.....끝까지 잘못된 글자로 표기되어서 조금 불편한데
이것도 수정하는 방법이 있을겁니다...얼핏 본거 같기고 하고요...
여튼 영문 자막 추출은 많이 편해졌습니다.
자막 씽크 맞추기는 진짜로 편합니다.
요즘 제가 올린 자막들의 씽크는 전부 이걸로 수정했습니다.
속도 변경도 편하고...(25fps→23.976fps)
씽크도 첫 문장과 마지막 문장을 동기화해서 돌려 버리면...중간 자막들은, 거의 날로 먹습니다.
가끔씩 1~2분 정도 편차가 발생하면....저는 1분 단위로 씽크를 동기화하니...씽크 오차를
거의 못 느낄정도이네요..
자막이 없이 하드코딩된 VOD영문은 영상과 파형정보를 이용하면 씽크 맞추기가 아주 쉽습니다.
.
.
제가 베타버전으로 작업을 하는데...
정말로 편합니다....
일부 단어의 경우 한번 잘못 저장하면.....끝까지 잘못된 글자로 표기되어서 조금 불편한데
이것도 수정하는 방법이 있을겁니다...얼핏 본거 같기고 하고요...
여튼 영문 자막 추출은 많이 편해졌습니다.
자막 씽크 맞추기는 진짜로 편합니다.
요즘 제가 올린 자막들의 씽크는 전부 이걸로 수정했습니다.
속도 변경도 편하고...(25fps→23.976fps)
씽크도 첫 문장과 마지막 문장을 동기화해서 돌려 버리면...중간 자막들은, 거의 날로 먹습니다.
가끔씩 1~2분 정도 편차가 발생하면....저는 1분 단위로 씽크를 동기화하니...씽크 오차를
거의 못 느낄정도이네요..
자막이 없이 하드코딩된 VOD영문은 영상과 파형정보를 이용하면 씽크 맞추기가 아주 쉽습니다.
.
.


인피니틀리 폴라 베어 (Infinitely Polar Bear, 2014)
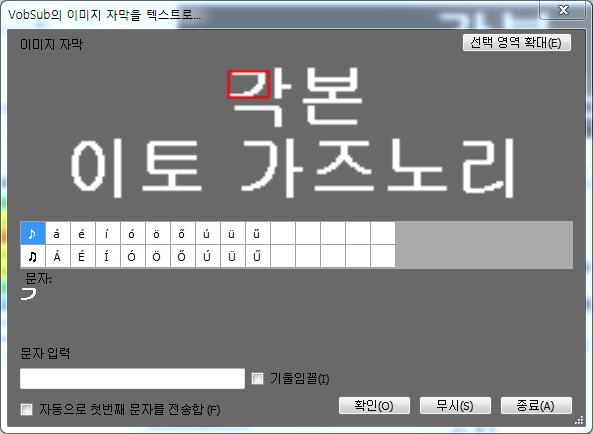
이미지 데이터 축적을 위해 자료실에 있는 위 자막으로, 두 번째로 섭변환하다가 의문이 생겨 질문합니다.
1. 몇 개의 모음(ㅏ, ㅣ, ㅐ 등)이 계속 이미지로 인식해서 Skip 했더니 '*'로 변환이 됩니다.
① 모음을 제대로 변환해서 수정하는 게 더 편한지요? ② 아니면 작업 효율성을 위해 별도로 설정해야 할 게 있는지 궁금합니다.
※ 게시물의 그림과 같이 설정해서 작업했습니다.
OCR 방식 : Binary image compare
이미지 데이터베이스 : Korean
공간의 픽셀 수 : 8 (default) → 15
오류 허용(%) : 1.1 (default) → 0.0
2. '공간의 픽셀 수'가 기본값(8)일 때와 그림처럼 15로 했을 때 차이점이 무엇인지도 알고 싶습니다.
이미지 데이터 축적을 위해 자료실에 있는 위 자막으로, 두 번째로 섭변환하다가 의문이 생겨 질문합니다.
1. 몇 개의 모음(ㅏ, ㅣ, ㅐ 등)이 계속 이미지로 인식해서 Skip 했더니 '*'로 변환이 됩니다.
① 모음을 제대로 변환해서 수정하는 게 더 편한지요? ② 아니면 작업 효율성을 위해 별도로 설정해야 할 게 있는지 궁금합니다.
※ 게시물의 그림과 같이 설정해서 작업했습니다.
OCR 방식 : Binary image compare
이미지 데이터베이스 : Korean
공간의 픽셀 수 : 8 (default) → 15
오류 허용(%) : 1.1 (default) → 0.0
2. '공간의 픽셀 수'가 기본값(8)일 때와 그림처럼 15로 했을 때 차이점이 무엇인지도 알고 싶습니다.

http://www.nikse.dk/subtitleedit/help
https://sourceforge.net/projects/tesseract-ocr-alt/files/
혹시 이게 도움이 될려나 모르겠네요...
https://sourceforge.net/projects/tesseract-ocr-alt/files/
혹시 이게 도움이 될려나 모르겠네요...
