문맥을 반영하는 DeepL 자동번역 자막 만들기 V2
DeepL 텍스트 나누기
https://drive.google.com/file/d/1qyuawC6XdvIMGCBZxiYsI4dBgSwtQF1F/view?usp=sharing
오늘은 DeepL 번역자막을 만드는 방법을 소개할까 합니다.
가장 성능이 좋기도 하고, 어차피 번역자막으로 감상할 것이라면
구글 자동번역 자막 같은 저품질 보다는, DeepL 번역자막이 낫겠지요
꼭 보고 싶은 작품이 있지만, 번역된 자막이 없다면 어쩔 수 없이
자동번역 자막에 의존할 수 밖에 없습니다. 자막없이 볼 수 있는
어학능력은 소수에게만 가능한 것이니까요.
>>>>>>>>>>>>>>> 주의 !! <<<<<<<<<<<<<<<<<<<<
시네스트는 번역기 자막의 업로드를 허용하지 않습니다.
DeepL이 아무리 성능이 좋다고 한들, 그걸로 자막을 만들면 1분만
봐도 번역기 자막인 것을 누구나 바로 알 수 있습니다.
제가 소개하는 방법은 자막이 없어서 어쩔 수 없이 번역기 자막에
의존해야할 때만 사용하셔야 합니다.
자동번역 자막을 공유하다가 글을 삭제당하거나 제제를 받는
일이 없도록 주의합시다.
자막을 번역하기 위해서 subtitle edit 에서 내보내기 할 때 3가지 옵션이 있습니다.
첫번째는 모든줄을 병합하고, 자막번호까지 제거해서 하나의 글로
만들 수 있습니다. DeepL에서 번역할때 이 형태가 가장 정확하게
번역되겠지만, 나중에 다시 자막으로 만들려면 엄청난 노가다를
해야 되기 때문에 옵션에서 제외합니다.
두번째는 모든줄을 병합하되, 자막번호는 남겨서 다시 자막으로
만들 수 있게 합니다. 그렇지만 자막번호를 통해서 다시 자막의
형태로 만들려면 분할과 재조립이라는 귀찮은 과정을 거쳐야 합니다.
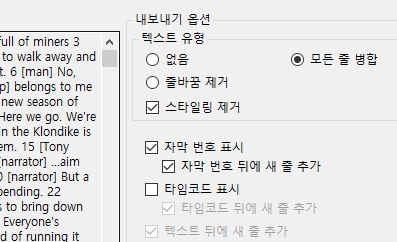
세번째는 자막번호마다 줄바꿈만 제거하고 한줄로 만들어서 번역하는 방법입니다.
이 방법은 번역문을 다시 자막으로 만들때 아주 간편합니다.
특별히 작업할 필요 없이 다시 원문자막의 형태로 바로 만들 수 있습니다.
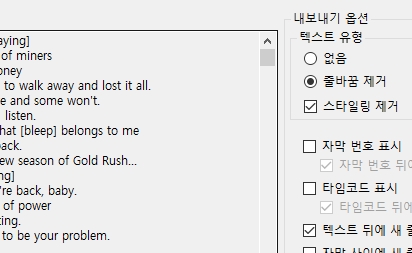
첫번째 옵션은 의미없고, 두번째와 세번째 형태의 문장을 DeepL이
어떻게 번역하는지 비교해 봅니다. 일단 아래의 사례를 통해서
어떤 차이점이 있는지 보겠습니다.
History is full of miners who made a lot of money
but didn't know when to walk away and lost it all.
2. 병합 / 자막번호 옵션
역사는 많은 돈을 벌었지만 언제 떠날지 몰라
모든 것을 잃은 광부들로 가득합니다.
3. 자막번호마다 한줄 옵션
역사는 광부들로 가득합니다. 많은 돈을 벌었던
하지만 언제 그만둬야 할지 몰라 모든 것을 잃었습니다.
확실히 병합해서 번역하는 것이 자연스러운 한국어
어순과 배치에 부합 합니다.
I don't want to downsize, you know?
We've spent so many years building up to
a size of company where I really enjoy it.
2. 병합 / 자막번호 옵션
규모를 줄이고 싶지 않아요. 우린 오랜 세월을 보내면서
제가 정말 좋아하는 회사 규모까지 키워왔어요.
3. 번호마다 한줄 옵션 번역
규모를 축소하고 싶지 않아요. 우리는 수년 동안 다음과 같은 기능을
구축하기 위해 정말 즐겁게 일할 수 있는 규모의 회사입니다.
이번 문장을 보면 확실히 문장을 병합해서 번역하면 똑똑한 중3이나
고1 학생 수준의 번역을 내놓는 것을 알 수 있습니다.
즉 DeepL 이 문맥을 파악해서 정확하게 번역하기 위해서는 문장들을
다른줄로 끊지 말고, 문장들 사이의 연결관계를 이해할 수 있는 형식으로
만들어줘야 한다는 것이겠죠.
그렇다면 결론은 분명합니다. 자막번호를 포함하는 문장병합 옵션으로
DeepL 번역을 진행하는 것이 정답이겠죠.
1. 원어 자막을 subtitle edit에서 메뉴 파일 -- > 내보내기 --- >
<일반 텍스트 파일로> 를 실행합니다.
2. 옵션에서 모든줄 병합을 선택, 자막번호 표시에 체크 합니다.
3. 이 자막번호들은 나중에 다시 자막의 형태로 만들어질 때, 분할하는
기준점이 됩니다. 그래야 자막 싱크가 맞아서 감상이 가능하니까요.

4. 만들어진 텍스트 파일을 열고 내용을 모두 복사한 후 MS 워드를
실행하고 붙여 넣습니다. docx 파일로 저장한 후 deepL에서 파일번역을
선택하고 첨부하여 업로드 합니다.
번역 언어에 한국어를 선택하면 번역이 시작되고, 번역이 완료되면
자동으로 다운로드 됩니다.
일반적인 자막 정도의 글자수 분량이라면 대부분 무료회원 파일번역이
가능한 분량일 겁니다. DeepL 회원 가입은 간단하므로, 무료회원으로
가입해서 파일번역을 통해 조금이라도 시간을 절약하고 불편함을
줄이는게 낫겠지요.
5. 다운받은 번역 docx 문서를 다른 이름으로 저장하기해서
txt 형식으로 저장합니다.
6. 이제 다운받은 번역문을 자막번호를 기점으로 한줄씩 나누어야 합니다.
이것이 이번 작업의 핵심입니다. 자막을 다시 만들어서 감상하는 것이
목적이니까요.
DeepL은 업로드한 영어원문을 번역할때 대부분의 자막번호는 무시하고 번역합니다.
문맥을 읽으면서 번역하기 때문에 중간에 삽입된 자막번호는 문맥과 상관없는
번호이므로 무시하기 때문이죠. 그래서 대부분의 자막번호는 있어야할 위치에
그대로 남겨둡니다.
그런데 무슨 이유인지 모르겠지만 어떤 경우에는 자막번호를 지워버리기도 합니다.
그리고 DeepL이 영어를 우리말로 번역하면서 어순을 완전히 뒤바꿀때 자막번호까지
바뀐 어순에 따라서 위치를 바꾸는 경우도 있습니다.
문장들이 복잡하게 얽혀서 영어에서 한글로 번역할때 어순의 변경이 크게 생기거나
구문이 복잡한 영어 문장들에서 이런 오류들이 집중적으로 일어나는 것을 알 수 있습니다.
여기서 문제가 생깁니다.
이런 자막번호를 원래대로 1, 2, 3 ,,,, 으로 이어지는 순서대로 수정해 주지 않으면
자막의 형식으로 돌아가기 어렵습니다. 원본 영문자막과 자막번호가
일치하지 않으면 싱크가 엉망이 되기 때문이죠.
이런 오류가 발생하는 갯수는 자막마다 다릅니다만, 자막 한편에 평균적으로
10개 정도 되는 듯 합니다.
이러한 문제는 사실 자막 형식 그대로 번역한다면 일어나지 않을 문제입니다.
그러나 조금이라도 더 정확하게 번역하기 위해서 자막형식을 완전히 버리고
다시 구성하는 방식을 취했기 때문에 이러한 불편이 생깁니다.
번역된 문장들을 처음부터 끝까지 쭉 읽어가면서 보통 1000-2000개 사이로 있는
자막번호들을 하나하나 체크해가면서 수동으로 수정하면 짜증나기 마련입니다.
사람이니까 빠트리고 수정 못하는 일도 생길테구요.
자막형태가 해체된 번역문을 다시 자막형태로 되돌리기 위해 몇가지 자동화 도구를
엑셀 매크로를 통해서 만들었습니다. 아래에서 이 매크로의 사용방법과 유의점을
설명하겠습니다.
7. <DeepL 텍스트 나누기>을 다운로드 합니다. 시네스트에서 다운로드가
안될 경우, 아래 구글 드라이브 링크에서 다운로드 하시면 됩니다.
혹시나 이 링크에서도 다운로드가 안되시면 댓글로 알려주세요
https://drive.google.com/file/d/1qyuawC6XdvIMGCBZxiYsI4dBgSwtQF1F/view?usp=sharing
8. <DeepL 텍스트 나누기> 다운로드 한 후 파일을 클릭해서 우클릭 하고
속성을 클릭합니다.
9. 속성 창의 보안항목에서 차단해제를 체크하고 적용을 클릭한 후
확인을 클릭합니다.

10. <텍스트 나누기.xlsm> 클릭해서 실행합니다. 그러면 엑셀이 실행됩니다.
상단에 보안경고 항목에서 <콘텐츠 사용>을 클릭해서 매크로를 사용 가능하게
합니다.

아래 매크로들을 사용해서 번역된 텍스트들을 자막번호 순서대로 자막형식에
맞게끔 분할할 것입니다.
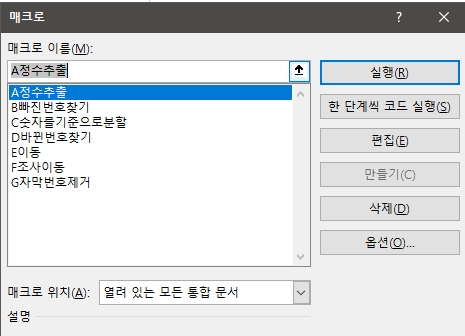
매크로를 실행하기 위해서는 엑셀 상단의 개발도구 탭에서 매크로를 클릭합니다.
혹시 개발도구 탭이 보이지 않는 분이라면 엑셀의 설정에 들어가서
리본사용자도구 --- > 개발도구 항목을 체크해 주시면 됩니다.
이제 각 매크로의 기능과 사용방법을 설명하겠습니다
1. 삭제된 번호 찾기
먼저 DeepL이 번역하면서 삭제해버린 자막번호를 찾는것이 가장 중요합니다.
자막번호를 제대로 입력해야 자막의 싱크가 맞아서 감상이 가능하기 때문이죠.
번역된 자막문을 모두 선택하고 복사해서 C1셀에 붙여넣습니다. C1셀에 정확히
붙여넣지 않으면 매크로가 실행되지 않습니다. 워드에서 변환한 파일에는 빈줄이
맨위에 한 줄 들어가기 때문에 그걸 삭제하고, 모두 선택후 복사합니다.
C1셀에 붙여넣은 후, <A-정수추출> 매크로를 실행합니다. 이 매크로는 숫자만 남기고
나머지 데이터는 모두 삭제합니다. 누락된 자막번호를 찾기 쉽게하기 위한 것입니다.
2. 다음으로 <B-빠진번호찾기>를 실행합니다. 그러면 대략 초반 자막번호 50번대 이내에서
빠진 번호는 옆 B열에 빈칸으로 나타나고, 50번대 이후로 빠진 번호는 C3부터 하나씩 열거됩니다.
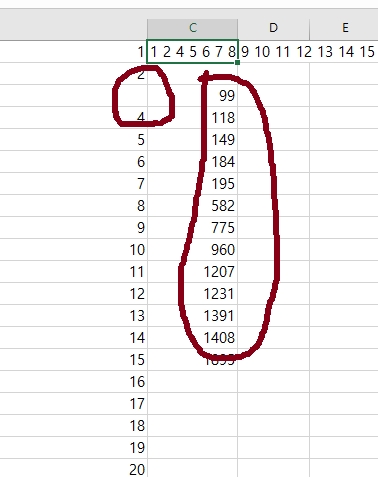
보시다시피, 50번대 이내에서 빠진 번호는 B열에 빈칸 3으로 표현되었고, 나머지
빠진 번호는 C3 이후로 쭉 열거되었습니다. 제가 길이가 긴 자막을 선택했더니
빠진 번호가 좀 많네요.
이 번호들을 드래그해서 복사한 다음에 메모장에 붙여넣습니다. 그리고 50 번대에서
빠진 자막 번호도 적어놓고요. 빠진 번호를 알았으니 이제는 DeepL이 순서를 뒤바꾼
번호를 알아야 합니다.
3. 순서가 뒤바뀐 번호 찾기
B열과 C열을 모두 선택해서 데이터들을 모두 삭제합니다. 그리고 C1에 다시 번역문을
모두 선택해서 붙여넣기 합니다.
C1에 번역문을 붙여 넣은 상태에서 <C-숫자를기준으로분할> 매크로를 실행합니다.
이 매크로를 실행하면 C1의 번역문 전체가 숫자를 기준으로 한칸씩 분할되어 B열에
해체됩니다. 자막번호 뿐만 아니라 모든 숫자들을 기준으로 분할되기 때문에 조금
이상한 형태겠지만 나중에 다시 정상적으로 조립할 것입니다.
4. 이제 <D-바뀐 번호 찾기> 매크로를 실행합니다. 앞서서 설명했듯이 DeepL이 영문을
한국어로 번역하면서 자연스러운 한국어 번역을 위해서 어순을 많이 바꾸는 작업을
했기 때문에 그에 따라서 자막번호도 문장과 같이 이동하는 경우가 자주 발생합니다.
이 매크로는 자막번호가 뒤바뀐 곳이 어디인지 표시합니다. 자막번호가 바뀐 곳은
D에 있는 셀에 2나 3으로 표시됩니다. 자막번호가 바뀐 곳 이외에도 이상한 곳에서
번호가 표시되기도 합니다만,
자막 번호가 바뀐 곳에만 신경쓰고 다른 곳은 그냥 무시하면 됩니다.
그리고 자막번호가 삭제된 곳에도 이 번호들이 나타나겠지만 이미 기록해
두었으니 이것도 무시하고 지나가면 됩니다.

282, 284, 283 으로 순서가 잘못되었다는 것을 D열에서 숫자 2로 표시해 주었습니다.
이렇게 자막번호가 바뀌는 부분들은 DeepL이 영어 어순을 한국어 어순으로 아주 많이
바꾼 경우가 대부분입니다.
이렇게 바뀐 번호들은 보통 하나의 문장안에 들어 있습니다. 바뀐 번호들 중에
한 문장안에 속하는 한개만, 앞서 빠진 번호를 적어두었던 메모장에 적어넣습니다.
이렇게 쭉 스크롤하면서 내려가면서 뒤바뀐 번호들을 하나씩 적어둡니다. 이 번호들은
딥엘이 번역하면서 영어와 우리말의 어순이 복잡하게 뒤섞였다는 뜻입니다.

그래서 삭제된 자막번호나 뒤바뀐 자막번호를 수정할 때는 그 번호가 있는 문장을 찾아 문장 앞뒤로
줄바꿈을 해줍니다. 이렇게 줄바꿈을 해서 시각적인 명료성을 갖추고 작업하는 것이 좋습니다.
왜냐하면 이렇게 오류가 생기는 자막번호들은 대부분 복잡하게 구성된 문장이기 때문에 번호들을
다시 배치하고, 수정하려면 약간 머리를 써야되는 경우가 대부분이라, 분명하게 드러나게 해놓고
수정하지 않으면 눈 아프고 짜증나서 못합니다.
이제 영문 자막을 참고해서 한국어 자막 문장 중에 삭제되거나 뒤바뀐 번호들이 어디에 삽입되면
좋을지 살펴봅니다. 이런 오류는 번역하기 까다로운 문장에서 생기는 경우가 많기 때문에 약간
고민스러울 때도 있을 겁니다.
결국 자막이란 영상을 보면서 다른 언어를 효율적으로 <즉시> 이해하기 위한 방법입니다.
그러므로 자막내용을 적절히 배분하면서도 대사의 타이밍과 크게 어긋나지 않아야 합니다.
이런 원칙에 따라서 가장 적당한 위치에 삭제된 자막번호를 삽입합니다. 뒤바뀐 번호의
경우에도 단순히 위치를 서로 바꿔주는 것 보다는 원문자막을 참고해서 적당한 위치를
잡아주는 것이 좋습니다.
위의 예를 들면 단순히 번호만 바꿔주는게 아니라


8. 이때 처음부터 자막번호 끝까지 한번에 이동하지 못하고 중간에 중단되고 완료되지
못했다면, 완료되지 못한 부분에 뭔가 오류가 있다는 뜻입니다. 자막번호를 제대로
수정하지 못했다던지, 삭제된 자막번호를 제대로 추가하지 못했다던지 하기 때문에
중단되었다면, 해당부분을 B열에서 수정한 후에 다시 <E-이동> 매크로를 실행 합니다.
자막이동이 완료되었다면, 처음부터 끝까지 쭉 스크롤하면서 빠진 부분은 없는지,
영문자막의 마지막 자막번호와 이 작업결과의 마지막 자막번호가 일치하는지 확인합니다.
영문자막의 끝번호가 1250 이라면, 이 결과물도 1250으로 일치해야 합니다. 그리고 엑셀에
있는 번호와 자막번호도 쌍으로 일치해야 합니다. 예를 들어 가장 옆에 표시되는 엑셀번호는
1300인데, 자막번호는 1299 라면 무언가 잘못된 것이므로 원인이 되는 부분을 찾아서 수정해
주어야 합니다.
그리고 하나의 셀 안에 자막번호가 두개나 그 이상이 들어 있다면 역시 무언가 잘못되었으므로
원인을 찾아서 수정해서 다시 정렬해야 합니다.
9. 조사오류 수정
이상없이 정렬되었다면 <F-조사이동> 매크로를 실행합니다.
DeepL은 대부분의 자막번호를 의미없는 것으로 간주하고 번역에 사용하지 않습니다만
약간 문장이 복잡해지는 경우 자막번호에 의미를 부여하고 번역에 사용하는 경우가
가끔 있습니다.
<가스 71가>, <비밀 85와> 처럼 실제로 번역에 사용하지 않아도 무방하지만
모든 텍스트의 의미를 어떻게든 완전하게 이해해 보려고 노력하는 과정에서 생기는
오류로 보입니다. 이런 것들은 <가스가 71> <비밀과 85>로 수정해줘야 하는 겁니다.
이런 오류를 바로잡기 위해서 <F-조사이동 매크로>는 자막번호 뒤에 조사가 붙어있을
경우 앞줄에 가야할 곳으로 해당 조사를 이동해서 붙여넣습니다. 물론 완벽하진 않지만
수동으로 수정하는 작업을 대부분 줄여줍니다.
10. 정상적으로 완료되었다면, <G-자막번호 제거> 매크로를 실행합니다. 번역문이
자막 순서대로 짜맞추어졌으니 문장 앞에 있는 자막번호는 더이상 필요없습니다.
삭제해야지요.
11. 완료 및 점검
모든 매크로의 실행이 완료되었습니다. 마지막으로 다시 한번, 이상한 부분은 없는지
체크해보고, 빼먹은 것은 없는지 점검해 봅니다. 문제 없다면 매크로작업을 마칩니다.
삭제된 자막번호를 다시 삽입하는 것과 자막번호가 뒤바뀐 것을 수정하는 것
이외에 모두 매크로로 자동화 했기 때문에, 원래 영문자막과 1:1 싱크로 되돌리는데
짧은 시간이면 충분합니다. 아마 오류가 적은 자막이라면 수정완료에 5분도 채
걸리지 않을 겁니다.
만일 자막번호가 깔끔하게 정리되어 완벽하게 정상순서로 채워진 번역문이라면
위의 매크로들을 실행하는데 1분도 안걸릴 겁니다. 사실 단순한 작업이죠.
여기서 의문이 생길 수 있습니다. 일본어 자막 같은 경우 한국어와
어순이 거의 대부분 일치합니다.
그러면 일본어 자막번역은 문장병합을 하지않고 줄바꿈 정도만 제거해서
번역하면 자막번호 삽입문제로 고민할 필요도 없고, 원문자막의 내용과
시간에 정확히 일치하는 자막이 나오는거 아닌가?
맞습니다. 사실 우리말과 어순과 단어가 비슷한 일본어 같은 경우
그냥 줄바꿈 제거 정도만해도 충분히 볼만한 번역이 나옵니다.
일본어의 경우에는 제가 매크로를 만들긴했지만, 저라도 이 방식으로
간단히 번역할 겁니다. 크게 차이가 없을테니까요.
그렇지만 영어는 우리말과 어순이 다르기 때문에 정확한 번역을
하기 위해서 이런 고생을 하면서 어거지로 자막을 만든 것이죠.
일본어든 영어든 그냥 원문 싱크와 대사 타임에 충실한 번역자막을
만들고 싶다면 간단합니다.
1. subtitle edit 에서 줄바꿈 제거하고, 자막번호도 타임코드도 모두
표시하지 않게 체크해서, 순수하게 자막내용만 한줄씩 나눠서
텍스트 파일로 내보내고,

2. DeepL에서 번역한 것을 다시 텍스트 파일로 저장한 후에
3. 번역문을 모두 선택하여 엑셀 A열에 붙여넣습니다.
4. 그러면 엑셀이 자동으로 아래와 같이 분리해서 다른 셀에 넣어줍니다.
아래와 같이 바로 붙여넣기가 되기 때문에 원문자막과 싱크와 내용이 동일한
자막파일이 바로 만들어지는 것이죠.

5. 이때 대사라인에 <-빨리하라고 -네, 알겠습니다> 이런 문장이 있다고 하면
엑셀에서 가끔씩 이걸 수식으로 판단하고 <=-빨리하라고 -네, 알겠습니다>
이렇게 표시하는 오류가 생길 수 있습니다. 아래와 같이 표시될 수 있습니다.
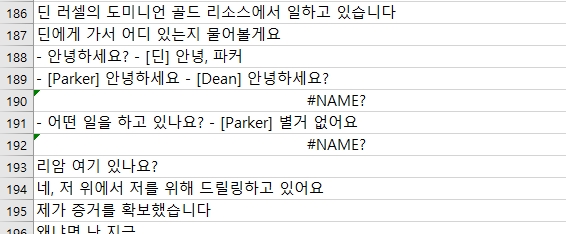
6. 이때는 아래와 같이 = 를 모두바꾸기로 삭제해줍니다. 바꿀내용을 공백으로 두고
모두바꾸기를 실행합니다. 그러면 제대로 표시됩니다.
7. 문장병합은 번역의 정확성이 좋은 장점이 있지만, 다시 자막으로
만들려면 번거롭고, 원문 자막라인의 단어 갯수와 번역문 자막라인의
단어 갯수를 비슷하게 되도록 만져줘야 좀더 좋은 자막이 나옵니다.
줄바꿈제거 옵션은 번역의 정확성은 떨어지지만 자막이 정확한 타임에
나오고 다시 자막으로 만들기 쉽습니다.
일본어가 아닌 다른 언어를 번역할때 둘중에 어느 방식을 선택할지는
각자의 선택입니다. 장단점이 있기 때문이죠.
이제 다음 단계로 이동합니다.
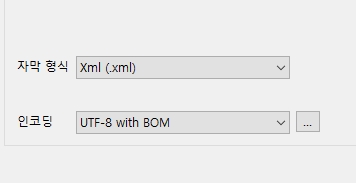
01. 이제 subtitle edit 에 도구 --- > 일괄 변환 기능을 사용해서, 원어 자막을
xml 형식으로 바꾸어 저장합니다. xml 형식으로 바꾸는 이유는 엑셀에서 자막을
불러와서 작업하기 위해서 입니다.
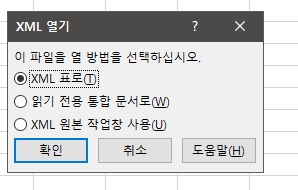
02. 엑셀을 추가로 실행해서 엑셀창을 하나더 띄웁니다. 그리고 저장한 xml 자막을
불러옵니다. xml 열기창에서 그대로 확인을 클릭합니다.
다음에 나오는 알림창도 확인을 클릭하고 불러오기 작업을 마무리 합니다.

훌륭하게 불러오기 되었군요.
03. 엑셀에서 분할 완료된 A열 한글자막 셀들을 처음부터 끝까지
선택한 후에 복사합니다.
04. 다시 xml 자막으로 이동해서, 텍스트 첫번째 셀을 선택한 후에
붙여 넣습니다.

05. 복사가 잘 됐는지 다시 한번 확인해 봅니다. 잘 된 것 같군요.
06. 이것을 다시 다른 이름으로 저장하기를 실행해서,
xml 형식으로 저장합니다.
07. 그리고 이 xml을 subtitle edit에서 불러옵니다. 잘 인식하는군요.

작업과정에서 줄바꿈이 모두 없어졌기 때문에, 메뉴의 도구 항목에서 일반적인 오류수정
기능으로 줄바꿈을 만들어 줍니다. 일반적인 오류수정에는 여러가지 기능이 있는데 그중에
긴줄을 자동으로 줄바꿈 해주는 기능이 있습니다.
이 기능을 이용해서 너무 길게 번역된 문장들을 줄바꿈 해줍니다.
08. 이제 다른 이름으로 저장하기를 실행하여 srt 나 smi 같은
자막형식으로 저장하면 작업은 완료된 것입니다.
09. 완료한 후에 번역이 어떤지 살펴봅니다.

그럭저럭 괜찮네요. 구글보다는 훨씬 나은 것 같습니다.
01. 영어자막의 타임코드에 맞추어서 번역자막을 만들기 때문에, 자연스럽지
않을 때가 가끔 있습니다. 그럴때는 개별 자막라인의 시간 길이를 1, 2초
늘리거나 줄여서 보기 편하게 해줘야 하는데, 수동으로 할 수 밖에 없습니다.
02. 봐줄만한 번역을 하기 위해서는 제대로 제작된 원어 자막을
사용해야 합니다. 특히 영어의 경우, 쉼표와 마침표가 제대로
찍히지 않으면 번역이 제대로 이루어지지 않습니다
쉼표와 마침표를 통해서 문장의 시작과 끝을 제대로 알려주지 않으면
DeepL이라도 조금 부족한 자막을 만들어 줍니다. 따라서 제대로 제작된
원어 자막을 통한 번역이 무엇보다 중요합니다.
04. 저는 한번보고 삭제할 영상들을 감상할 목적으로 이 매크로들을
만들었습니다. 그렇지만 계속 자주볼 영상이고, 좀더 자연스러운 자막을
만들고 싶은 경우도 있을 겁니다.
그럴때는 원문자막과 번역문의 내용을 비교하면서 자막번호들의 위치와
번역내용을 좀더 세심하게 편집한 이후에 이 매크로들을 실행하면 훨씬
나은 자막이 나올 겁니다.
05. 어쨌든 DeepL 번역자막은 그럭저럭 볼만합니다. 그래봤자 자동번역
자막일 뿐이지만, 10-15분 수정해주고 의미가 충분히 이해되는 자막을
만들 수 있다는건 꽤 좋습니다.
특히 남들이 자막을 만들어줄 가능성이 거의 없는 외국 다큐 같은 것에
관심을 갖고 있다면 정말 고마운 도구일 겁니다.







처음부터 잘 따라서 하고있는데 5번 이동에서 에러가 나내요 ㅠ.ㅠ
어디부분이 잘못되어서 일까요?
' B1 셀의 데이터를 A1 셀로 복사합니다.
Range("A1").Value = Range("B1").Value
lastNum = Split(Range("B1").Value, " ")(0) <-----이부분이 문제라고 나오네요...
' B열의 범위를 설정합니다. 데이터가 입력된 마지막 셀까지의 범위를 찾습니다.
Set rng = ThisWorkbook.Sheets("Sheet1").Range("B2:B" & ThisWorkbook.Sheets("Sheet1").Cells(Rows.count, "B").End(xlUp).Row)
강좌가 너무 좋습니다.
항상 보고싶은 영상들이 있어도 영어실력은 안되고...그나마 구글번역으로 만족했었는데....이렇게 좋은 툴을 아낌없이 배풀어주셔서 감사합니다.
자체자막 1편, DeepL 번역 자막 1편, Sub자막 1편 모두 성공했습니다. 저에게는 위 3가지 방법이 너무 귀한 신세계입니다.
이젠 플루이드 모션에 도전해봐야겠습니다..전 항상 플루이드 모션 작동으로 보고있는데...강좌님께서 모든영상이 플루이드 모션이 좋은것이 아니라고하셔서
이번에 저도 자동으로 선택하는것으로 변경 시도해보려고요...전 주로 블루 1080p, 2160p 영상을 감상하는데...그럼 플루이드 모션을 사용안하는게 낫는지..고민 됩니다.
당연 LAV는 같이 사용합니다.